Game Stat Tracker
League of Legends Champion Analytics Platform (In Development)
This project is an in-development analytics platform designed to aggregate, process, and rank League of Legends champion performance using live data from the Riot Games API. The system ingests raw match and store data, runs scheduled calculations, and produces derived metrics that power leaderboards and tier-based champion rankings.
The focus of the project is backend data processing, metric design, and building a scalable pipeline capable of turning high-volume game data into meaningful, comparable insights.
Problem
While the Riot Games API exposes extensive raw match data, it does not provide higher-level analytics such as relative champion strength, normalized rankings, or aggregated performance metrics across large sample sizes. Raw stats alone are noisy, difficult to compare, and often misleading without additional processing.
Solving this problem requires:
Reliable data ingestion at scale
Scheduled processing and recalculation
Carefully defined metrics
Normalization across champions, roles, and patches
This project was built to explore those challenges end-to-end.
Data Ingestion & Scheduling
The platform integrates directly with the Riot Games API to ingest match data and related champion information. Because this data changes continuously, ingestion is handled through scheduled background jobs rather than real-time requests.
Key elements of the ingestion pipeline include:
Cron-based jobs to fetch new data on a defined schedule
Rate-limit–aware API access
Separation of raw data storage from processed metrics
Incremental updates to avoid redundant data processing
This approach ensures data freshness while maintaining stability and API compliance.
Metric Calculation & Processing Pipeline
Raw game data is processed into structured, comparable champion metrics through a calculation pipeline that runs independently of the frontend.
The processing layer:
Aggregates champion performance data across matches
Normalizes results to reduce sample-size bias
Applies weighted calculations to smooth statistical outliers
Supports recalculation as new data or patches are introduced
These calculations produce a consistent metric foundation that can be reused across multiple views.
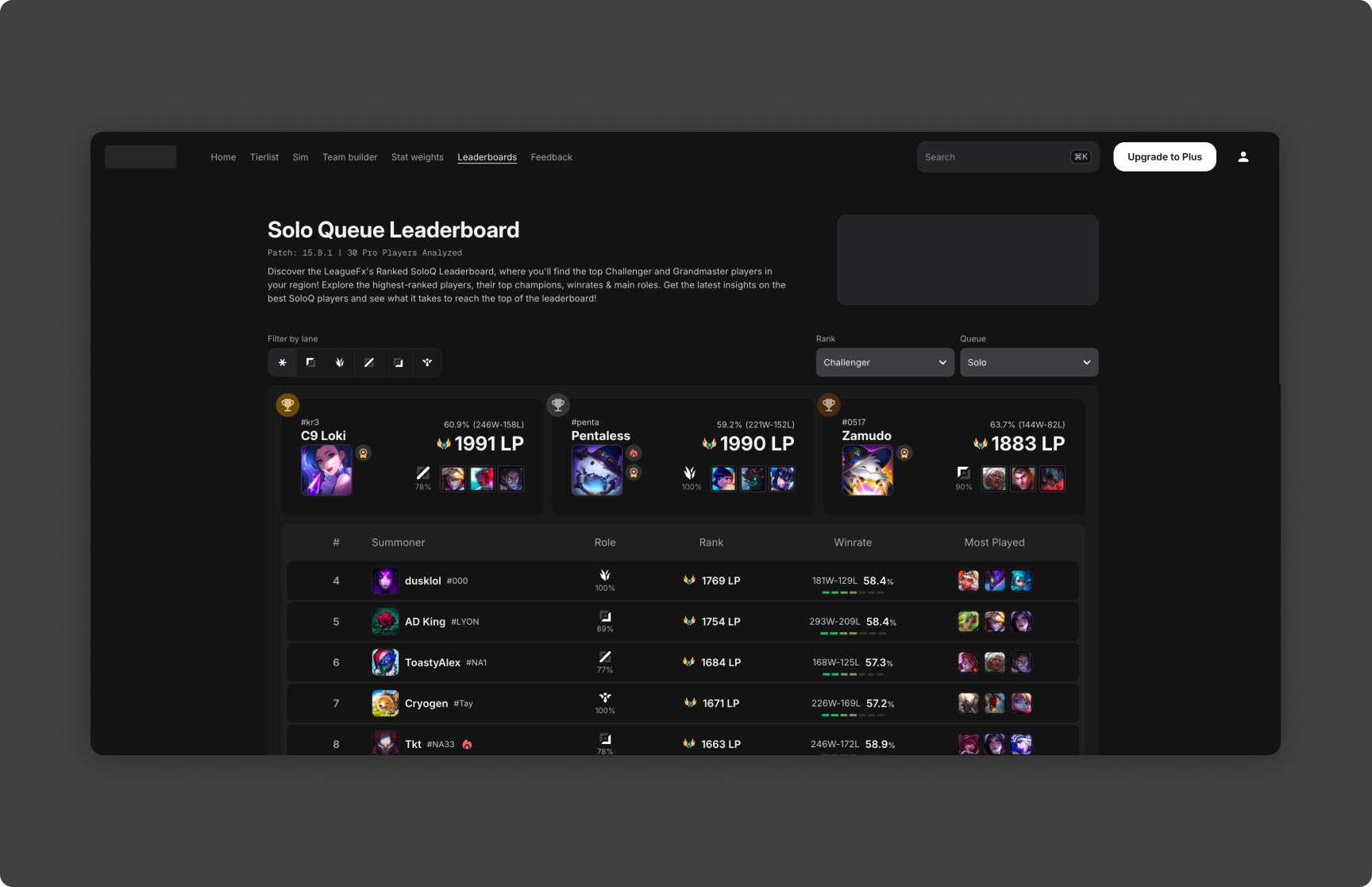
Champions are ranked based on calculated performance scores, allowing relative comparison across the entire roster.
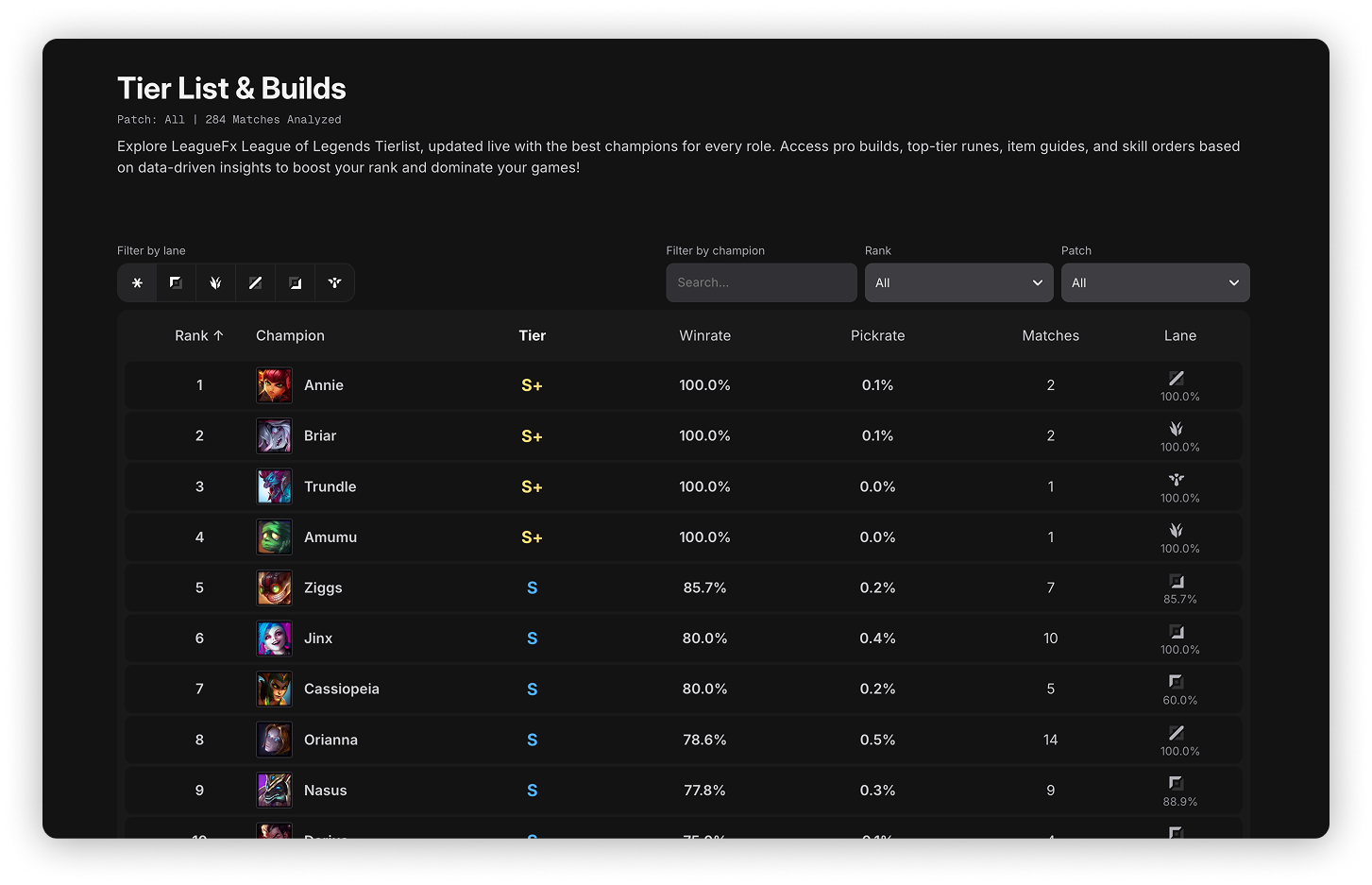
Tier-Based Rankings
Champions are grouped into tiers based on metric thresholds, making it easier to interpret relative strength without relying solely on raw rankings.
Both views are generated from the same underlying data pipeline, ensuring consistency and repeatability.
Technical Focus
This project emphasizes backend architecture and data workflows over UI polish.
Key technical areas include:
External API integration
Scheduled background processing
Data modeling and persistence
Metric definition and normalization
Separation of ingestion, computation, and presentation layers
The system is intentionally designed to support future expansion without requiring changes to the core data pipeline.
Status
This project is currently in active development. Core ingestion, scheduling, and metric calculation systems are implemented, with ongoing work focused on refining calculations, improving data coverage, and expanding frontend visualization.