Backend & API Engineering
Building Penn State’s Backend Foundation: APIs, Integrations, and Data Architecture
When I began working on backend and API engineering at Penn State, there were major systemic gaps beneath the surface of every web property. There was no centralized way to expose shared content across multiple colleges and programs. Enrollment systems weren’t connected to our websites, making it impossible to measure conversions or route form data reliably. And analytics tracking was inconsistent, fragmented, and disconnected from the component architecture that powered our UI.
The frontend could only scale so far without a backend foundation. My work focused on building that foundation: a federated API layer, form and CRM integration, and a standardized analytics model tied directly to components in the design system.
Modular GraphQL Fragment Architecture for Reusable Queries
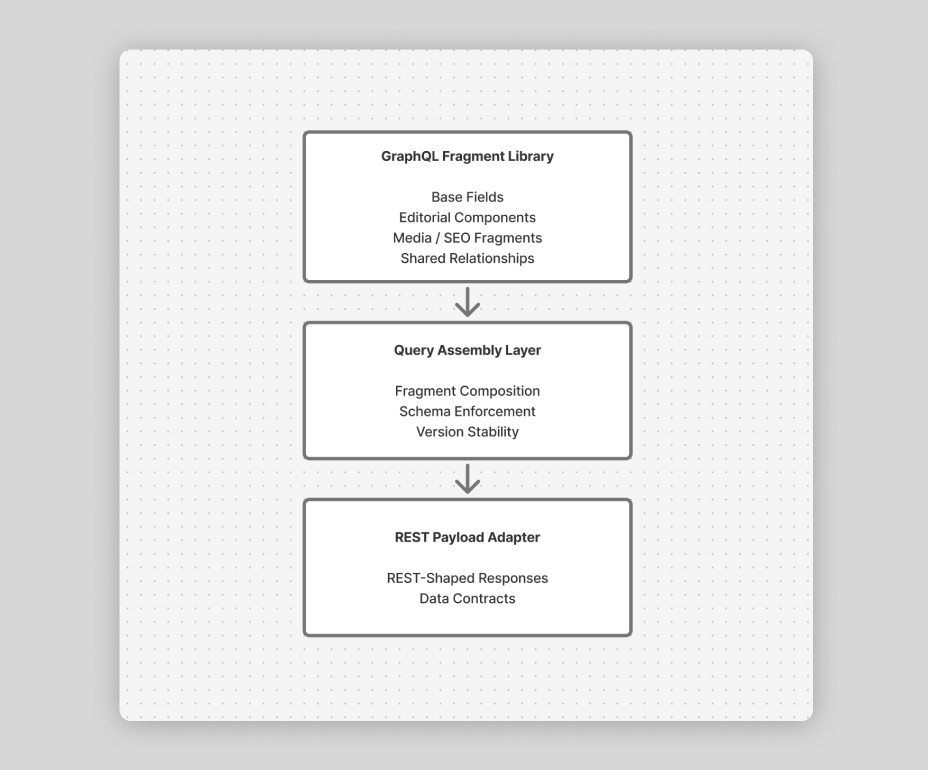
Before this work, each site defined its own GraphQL queries from scratch. This led to duplicated logic, inconsistent data shapes, breaking changes, and no ability to share query patterns across applications.
To fix this, I engineered a modular GraphQL fragment system that allows developers to build queries from reusable building blocks.
Key features include:
1. Fragment-based composition
I created a shared set of GraphQL fragments representing:
Base fields for content types
Layout and editorial component fields
Reusable metadata, images, and SEO fields
Common relationships and nested data
Developers can now compose queries by importing fragments rather than rewriting entire blocks of GraphQL.
2. REST-friendly assembly
Although our downstream consumers use REST, many still needed highly structured and predictable data. I built utilities that assemble fragments into REST-shaped payloads, making GraphQL modularity work seamlessly in our API layer.
3. Schema stability
When fields change or components evolve, updating a fragment updates the entire ecosystem—without searching for every instance manually.
This fragment architecture reduced code duplication dramatically and gave the API layer a predictable, maintainable structure for content access.
Creating a Federated REST API for Shared University Content
Penn State runs dozens of sites serving thousands of pages across colleges, departments, and administrative units. Yet there was no shared API to deliver reusable content across this ecosystem. Content had to be duplicated or manually synced between spaces, leading to:
Inconsistencies in program information
Repeated editorial work
Divergent schemas
Broken references across environments
High engineering overhead for cross-site changes
I designed and implemented a federated REST API that aggregates data across Contentful spaces and exposes a unified schema to all sites. This allows applications to pull:
Shared brand components
Program and academic information
University-wide announcements
Reusable editorial blocks
Cross-tenant structured data
The API became the connective layer allowing multi-tenant applications to access consistent, centrally managed content—without duplicating entries across dozens of spaces.
Integrating Enrollment Forms With Slate CRM
Before this work, forms on Penn State’s sites weren’t connected to Slate, the university’s enrollment CRM. This created serious problems:
Leads weren’t reliably captured or attributed
Conversion data had gaps
Enrollment teams couldn’t track where form submissions originated
Multi-step journeys were nearly impossible to measure
Developers had to manually build and maintain isolated form handlers
I architected and implemented the complete form integration pipeline:
A standardized form component system in React
Validation and data normalization
Secure API submission to Slate
Error handling and fallback logic
Environment configuration for sandbox/QA/production testing
Logging and debugging tools for enrollment teams
This transformed enrollment from guesswork into a measurable, repeatable, integrated workflow.
Building an Analytics Model for Component-Level Tracking
Analytics was another major gap across the university’s digital ecosystem. Each site implemented analytics differently, often manually. There was no consistent pattern for identifying components, tracking user behavior, or segmenting interactions.
The root problem was simple:
You can’t track meaningful interactions if components don’t have standardized identities.
I solved this by creating a component-level analytics system, which included:
1. A global component ID strategy
Every UI component receives:
A stable, unique ID
A semantic label
A traceable hierarchy reference
This standardized the tracking footprint across all sites.
2. Tag Manager integration
I integrated the design system directly with Google Tag Manager, enabling:
Automatic event dispatch
Interaction-level tracking (clicks, hovers, impressions)
Component metadata attribution
Funnel-level reporting tied back to UI elements
3. Analytics hooks embedded in the design system
Common interactions like button clicks, card hover events, slider engagements, and form submissions all now trigger standardized analytics signals.
This gave marketing and leadership teams visibility into:
What components users interact with
Which patterns convert best
Which parts of the page users ignore
How program pages perform across departments
For the first time, analytics became tied to actual UI patterns, not arbitrary DOM selectors.
The Result: A Connected Backend That Powers a Multi-Tenant University Platform
The backend engineering work established the missing infrastructure Penn State needed to scale its digital ecosystem.
Impact:
A federated REST API now serves consistent content across all university domains.
Enrollment forms integrate directly with Slate, closing conversion gaps and improving data quality.
Analytics is now component-driven, reliable, and standardized across all sites.
Developers have repeatable patterns for forms, tracking, and data access.
Leadership has clearer visibility into site performance and user behavior.
This backend foundation supports the frontend design system, the monorepo, and all future expansion of Penn State’s digital footprint.