Platform infrastructure & automation
@da_poling| (1y ago)
Thirty percent of our rebuilds were triggered by editors publishing redirects.
That number took a while to surface because nobody was measuring it. Each site had its own repository, its own deployment process, its own interpretation of how things should work. When a content editor updated a redirect in the CMS, the entire site rebuilt. On Gatsby, with a cold cache, that could mean hours. Teams had learned to work around it by scheduling publishes, batching changes, and accepting platform slowness as a fixed cost of doing business. Nobody connected the symptom to the cause because nobody had visibility across the whole system.
That is what institutional drift looks like up close. Not a single catastrophic failure, but dozens of small accommodations that accumulate into something very hard to move.
The sites themselves told the same story. Each one had been built by an independent team, pulling from a shared brand that existed more as aspiration than specification. The result was multiple versions of navigation, layout shifts between domains, and fractured user journeys where moving from one Penn State property to another felt like leaving the university entirely. Iframes were everywhere, teams embedding other sites to avoid rebuilding shared UI they did not control. The debt was visible in the experience.
The migration from Gatsby to Next.js on Vercel improved build times, but build time was never the real problem. It was a symptom of an architecture with no center. The monorepo gave it one.
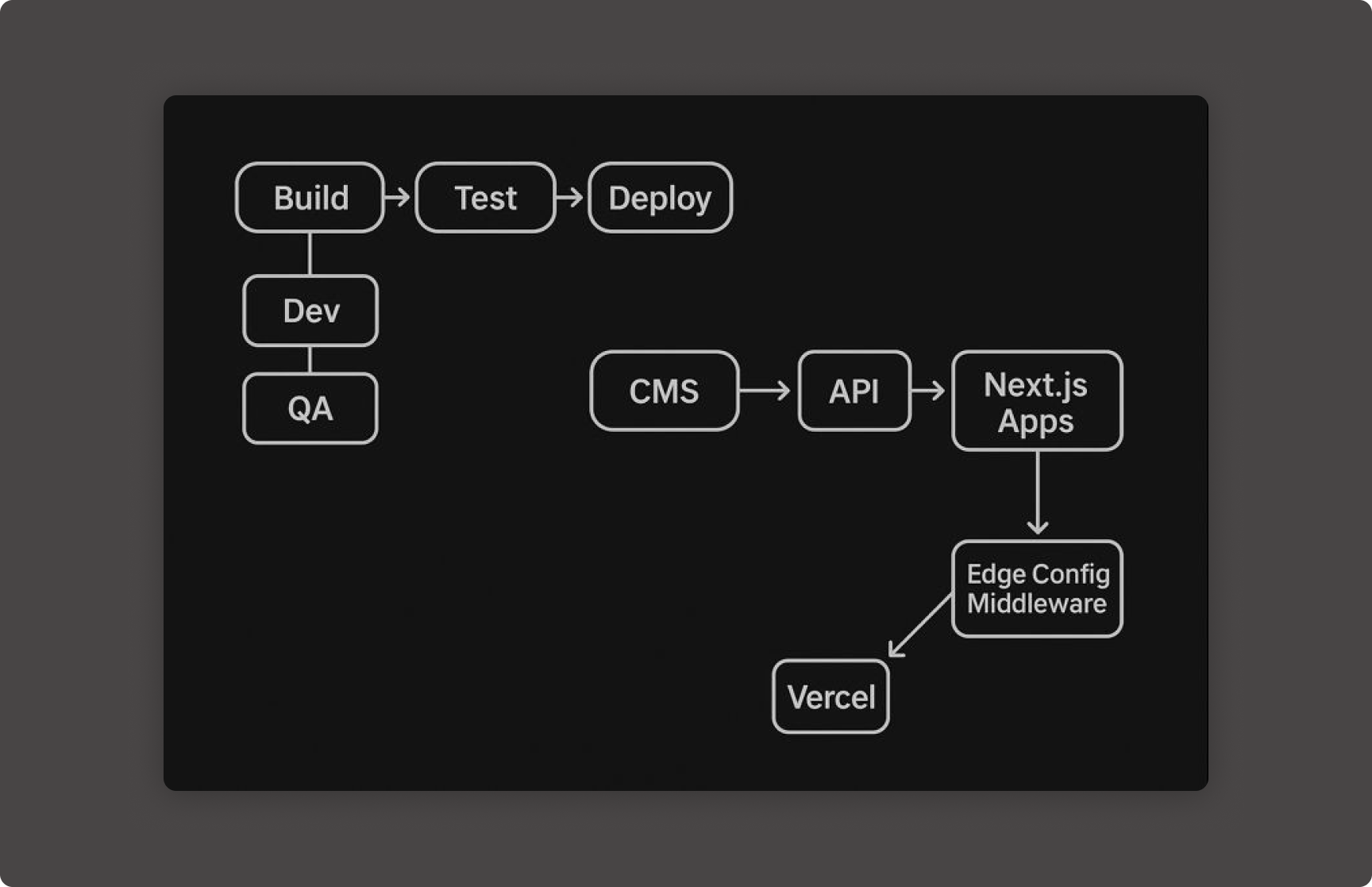
What centralization changed
Centralizing into a single multi-package repository changed what was possible. Shared components, shared utilities, and shared schemas were versioned together and governed from one place. Teams maintaining local copies of the same navigation component moved to a single source. When behavior changed, it changed everywhere at once. Drift stopped accumulating because the conditions that produced drift were removed.
Redirect architecture was a specific problem with a specific fix. Moving redirect logic into Vercel Edge Config made updates instant and removed rebuilds entirely. Thirty percent of rebuild triggers, gone. The deeper win was instrumentation. The number existed because the pipeline became observable enough to measure it.
You cannot fix what you cannot see, and most of the platform's problems had been invisible for a long time.
Automation as platform clarity
The CI/CD work, GitHub Actions, Playwright, standardized promotion paths, and a site boilerplate, was less about tooling for its own sake and more about making platform behavior legible to the teams using it. Automated tests created a defined release threshold instead of relying on whoever was available to click through manual checks. Standardized environments kept stage and production behavior aligned. Boilerplate made new sites a configuration decision rather than a weeks-long setup effort.
What I took from it
The strongest takeaway was not one I expected going in: refactoring at this scale is not evidence of failure. It is evidence of growth. The prior systems were appropriate for the organization that built them. They became inappropriate as the platform scaled and teams multiplied. This was not mistake correction. It was infrastructure redesign so the next growth phase would not require the same level of intervention again.
The remaining problem is harder. The platform works. The question is whether it works for an engineer arriving on day one with no context. A system that depends on institutional knowledge is not finished. Making it developer-agnostic, clear enough, documented enough, and opinionated in the right places, is the part that still does not have a clean ending.